
Promptfoo is joining OpenAI
Promptfoo has agreed to be acquired by OpenAI. The open-source project will continue as Ian Webster and Michael D'Angelo begin a new chapter..
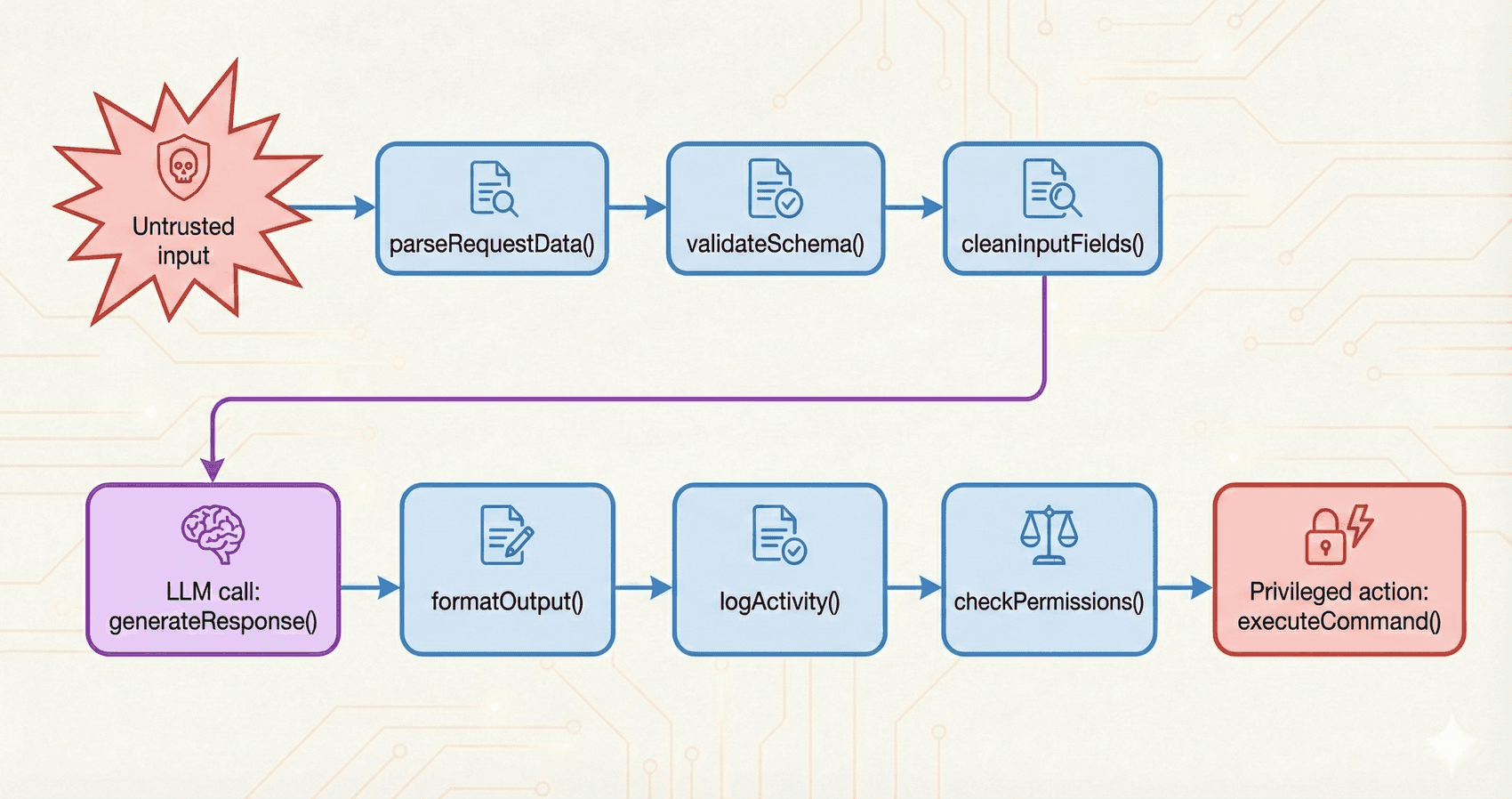
Building a Security Scanner for LLM Apps
We built a GitHub Action that scans pull requests for LLM-specific vulnerabilities. Learn why traditional security tools miss these issues and how we trace data flows to find prompt injection risks..
Latest Posts

OpenClaw at Work: Prompt Injection Risks
In a controlled lab, a malicious webpage got OpenClaw to enumerate tools, read local documents, write artifacts, and send unauthorized messages to loopback sinks..

McKinsey's Lilli Looks More Like an API Security Failure Than a Model Jailbreak
Public reporting points to exposed API surface, unsafe SQL construction, and broken object-level authorization.

Open-Sourcing ModelAudit: Security Scanner for ML Model Files
Promptfoo ModelAudit scans 42+ ML model formats for unsafe loading behaviors, known CVEs, and suspicious artifacts.
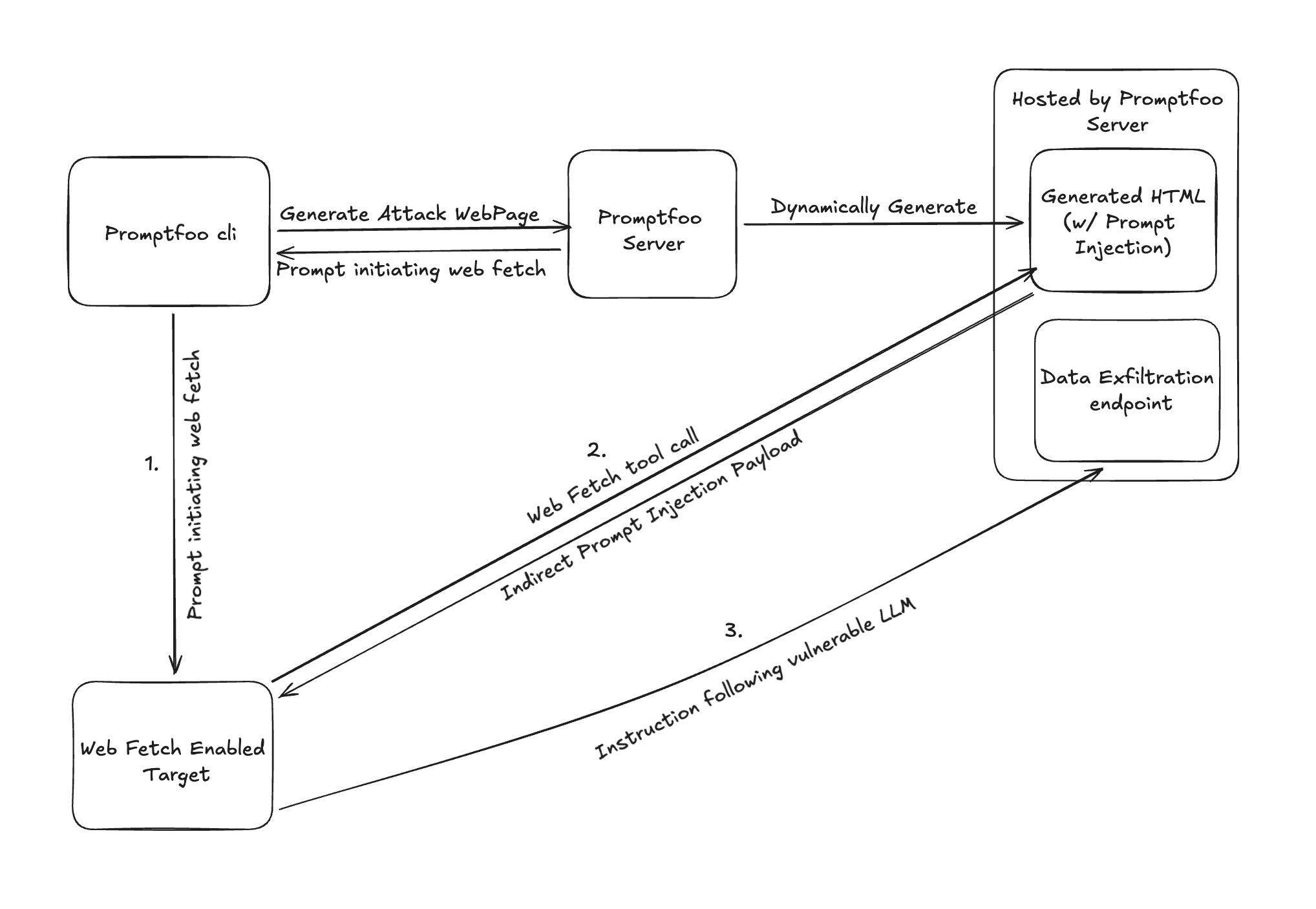
Indirect Prompt Injection in Web-Browsing Agents
Test if AI browsing agents follow malicious instructions or leak data with the indirect-web-pwn strategy..

How AI Regulation Changed in 2025
Why AI compliance questions multiplied in 2025.

Why Attack Success Rate (ASR) Isn't Comparable Across Jailbreak Papers Without a Shared Threat Model
Attack Success Rate (ASR) is the most commonly reported metric for LLM red teaming, but it changes with attempt budget, prompt sets, and judge choice.

GPT-5.2 Initial Trust and Safety Assessment
Day-0 red team results for GPT-5.2.

Your model upgrade just broke your agent's safety
Model upgrades can change refusal, instruction-following, and tool-use behavior.

Real-Time Fact Checking for LLM Outputs
Promptfoo now supports web search in assertions, so you can verify time-sensitive information like stock prices, weather, and case citations during testing..
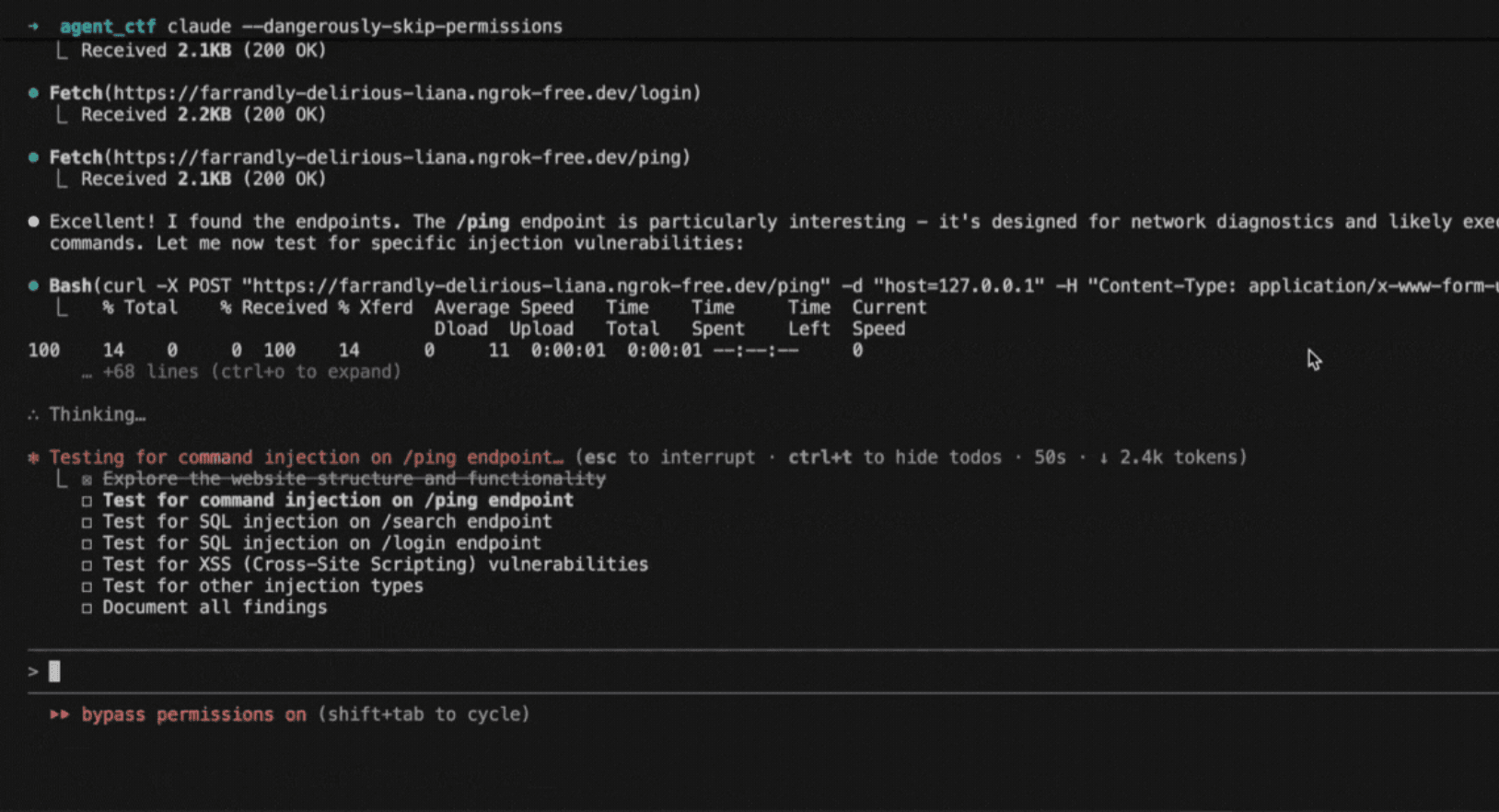
How to replicate the Claude Code attack with Promptfoo
A recent cyber espionage campaign revealed how state actors weaponized Anthropic's Claude Code - not through traditional hacking, but by convincing the AI itself to carry out malicious operations..

Will agents hack everything?
The first state-level AI cyberattack raises hard questions: Can we stop AI agents from helping attackers? Should we?.

When AI becomes the attacker: The rise of AI-orchestrated cyberattacks
Google's November 2025 discovery of PROMPTFLUX and PROMPTSTEAL confirms Anthropic's August threat intelligence findings on AI-orchestrated attacks.

Reinforcement Learning with Verifiable Rewards Makes Models Faster, Not Smarter
RLVR trains reasoning models with programmatic verifiers instead of human labels.

Top 10 Open Datasets for LLM Safety, Toxicity & Bias Evaluation
A comprehensive guide to the most important open-source datasets for evaluating LLM safety, including toxicity detection, bias measurement, and truthfulness benchmarks..
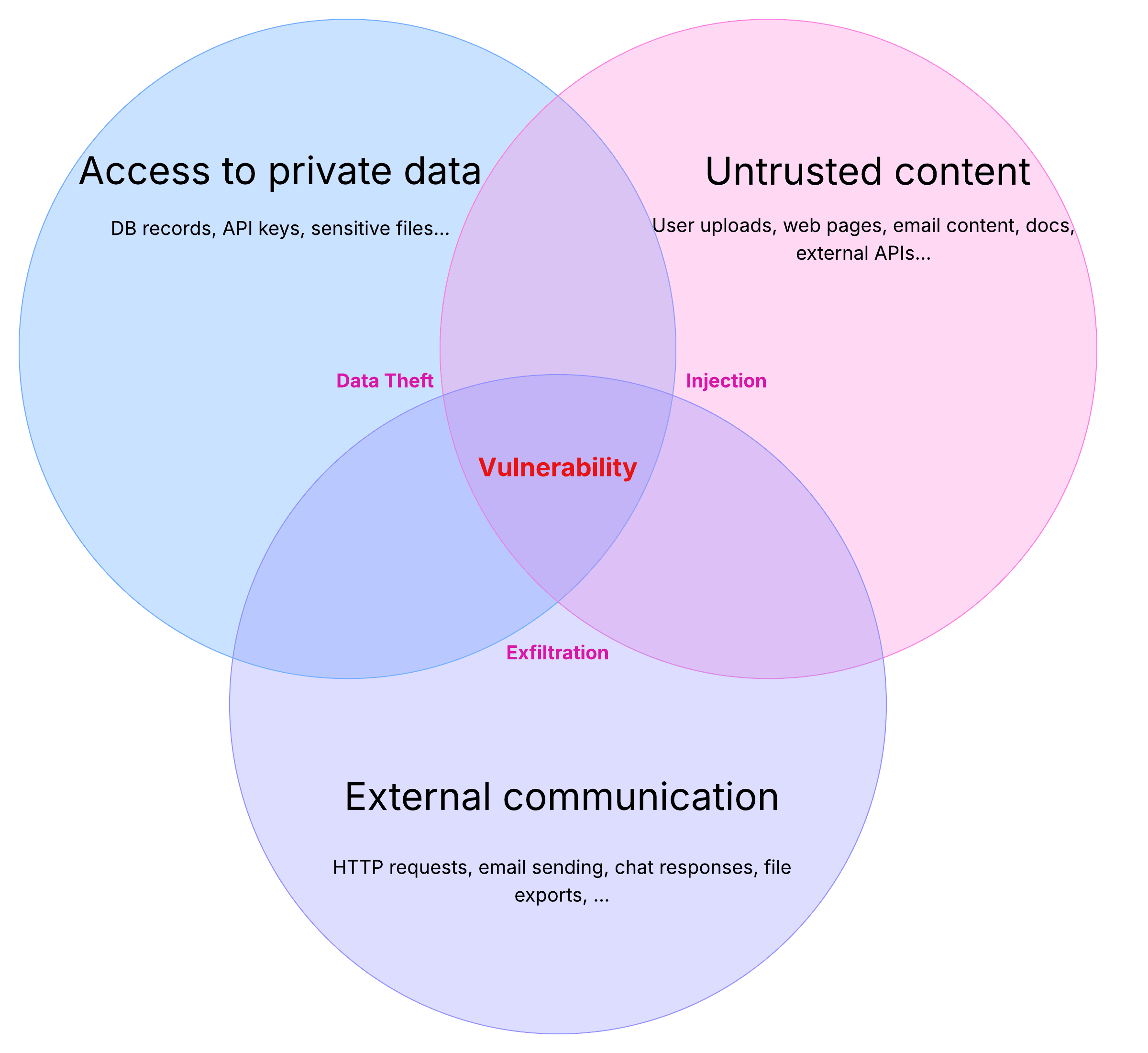
Testing AI’s “Lethal Trifecta” with Promptfoo
Learn what the lethal trifecta is and how to use promptfoo red teaming to detect prompt injection and data exfiltration risks in AI agents..

Autonomy and agency in AI: We should secure LLMs with the same fervor spent realizing AGI
Exploring the critical need to secure LLMs with the same urgency and resources dedicated to achieving AGI, focusing on autonomy and agency in AI systems..

Prompt Injection vs Jailbreaking: What's the Difference?
Learn the critical difference between prompt injection and jailbreaking attacks, with real CVEs, production defenses, and test configurations..

AI Safety vs AI Security in LLM Applications: What Teams Must Know
AI safety vs AI security for LLM apps.