Building trust in AI with Portkey and Promptfoo
This guide was written by Drishti Shah from Portkey, a guest author contributing to the Promptfoo community.
Supercharge Promptfoo runs with Portkey
AI models are powerful, but teams still face the challenge of knowing whether they can trust outputs in production. That's why evaluation has become central to every workflow.
Promptfoo gives you the framework to test prompts, compare models, and red-team systems. Portkey adds the infrastructure layer to make those evaluations scalable and production-ready.
Together, Promptfoo and Portkey help teams close the trust gap in AI, making it possible to evaluate the right prompts, across any model, with the observability and controls needed for real-world deployment.
Manage and version prompts collaboratively
With Portkey, you can store your prompts in a central library with history, tags, and collaboration built in. Promptfoo can reference these production prompts directly, ensuring evals always run against the latest (or tagged) version your team is using.
Example config
prompts:
- 'portkey://pp-customer-support-v3'
providers:
- openai:gpt-5
tests:
- vars:
customer_query: 'How do I reset my password?'
Instead of running evals on a local snippet, Promptfoo is now testing the production prompt stored in Portkey. Teams can review changes, roll back if needed, and lock evals to specific versions for cleaner comparisons.
When eval suites include adversarial test cases (like prompt injection attempts), Promptfoo effectively becomes a red-team harness for your Portkey-managed prompt — giving you confidence that the actual prompt in production holds up under pressure.
Run Promptfoo on 1600+ models (including private/local)
Portkey's AI gateway for Promptfoo allows you to run the same eval suite across 1,600+ models from OpenAI and Anthropic to AWS Bedrock, Vertex AI, and even private or self-hosted deployments.
prompts:
- 'Summarize the following text: {{text}}'
providers:
- id: portkey:gpt-5
label: GPT-5 (via Portkey)
config:
portkeyApiKey: ${PORTKEY_API_KEY}
portkeyApiBaseUrl: https://api.portkey.ai/v1
portkeyProvider: openai
- id: portkey:llama-4-scout-17b-16e-instruct
label: Llama 4 Scout 17B Instruct (via Portkey)
config:
portkeyApiKey: ${PORTKEY_API_KEY}
portkeyApiBaseUrl: https://api.portkey.ai/v1
portkeyProvider: meta
tests:
- vars:
text: 'AI evaluation is critical for production deployments...'
With this setup, you can run one test suite across multiple providers, no rewiring or custom adapters needed.
This makes it simple to compare model quality, latency, and cost side-by-side, whether the model is commercial, open source, or running in your own environment.
Promptfoo evals often fire thousands of requests at once. Without safeguards, that can quickly run into provider rate limits, retries, and inconsistent results.
Portkey helps keep runs stable and predictable:
- Load balancing: smooth out traffic and avoid hitting rate limits.
- Automatic retries: recover gracefully from transient provider errors.
- Response caching: return cached outputs for identical inputs, so repeat runs are faster and cheaper.
This ensures your CI/CD pipelines and large-scale evaluation runs are reliable—no more flakiness from bursty test cases.
Elevate security testing with Promptfoo red-teaming + Portkey
Promptfoo makes it easy to run adversarial test cases against your prompts—from prompt injections and jailbreak attempts to data exfiltration and toxic content checks. These red-team suites help uncover vulnerabilities before they reach production.
With Portkey in the loop, red-teaming becomes even more powerful:
- Unified orchestration: run red-team suites against any model through the same Portkey endpoint.
- Complete observability: Portkey logs every adversarial request and response, including latency, tokens, and cost.
- Better diagnostics: filter results by metadata, workspaces, or trace failures in Portkey's logging UI.
Together, Promptfoo and Portkey turn red-teaming from a one-off exercise into a repeatable, production-grade security practice.
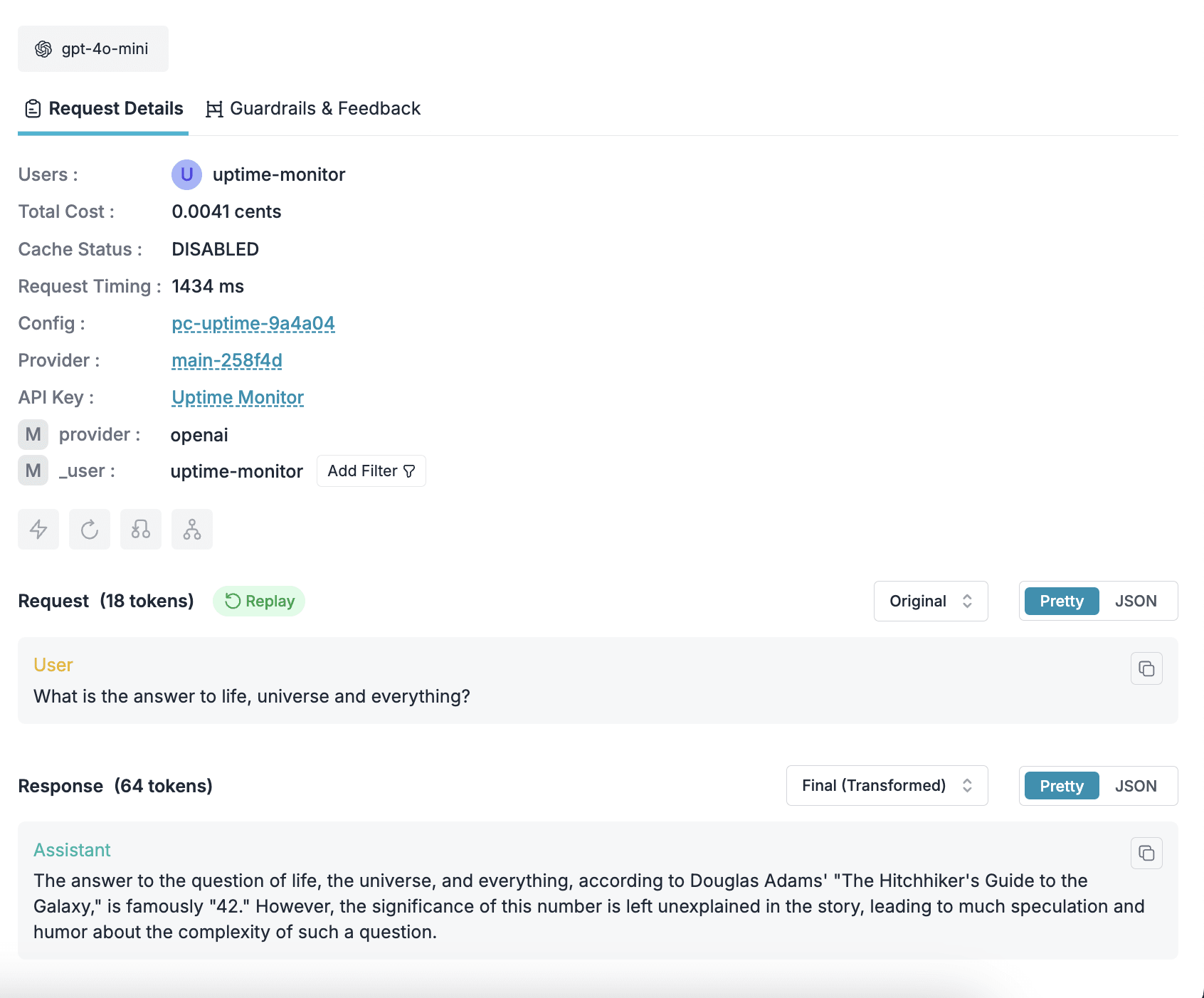
Gain detailed logs and analytics for every run
Every eval in Promptfoo produces valuable signals, but without proper logging, those signals get lost. Portkey automatically captures full-fidelity logs for each Promptfoo request:
- Request & response bodies: see exactly what was sent and returned
- Tokens & cost: track usage and spend across runs
- Latency & errors: measure performance and diagnose issues
You can also send custom metadata with each request — for example, tagging by test suite, commit SHA, or scenario. That makes it easy to slice results later by branch, experiment, or release cycle.
Quick start guide
Getting started is straightforward:
- Point your Promptfoo providers to Portkey (
portkeyApiKey+portkeyApiBaseUrl). - Reference production prompts stored in Portkey using the
portkey://syntax. - (Optional) Add metadata, caching, or rate limits for more stable runs.
That's it! Your Promptfoo evals now run with Portkey's infrastructure layer.
👉 Refer to the detailed documentation on Promptfoo and Portkey for setup instructions and advanced configuration.
Closing
Promptfoo gives teams the framework to run evals and red-team LLMs. Portkey adds the operational layer to make those evals collaborative, multi-model, observable, and production-ready.
Together, they help close the trust gap in AI — letting you run the right prompts, on any model, with the governance and reliability you need at scale.
👉 Try Portkey in your next Promptfoo run, and see how much smoother your evals become.