GPT-5.2 vs o3: Benchmark on Your Own Data
OpenAI's o3 is a reasoning model designed to spend more time thinking before responding, excelling at complex math and logic tasks.
GPT-5.2 outperforms o3 on most general benchmarks, but o3 still leads on deep reasoning tasks like advanced math and multi-step logic problems.
This guide describes how to compare o3 against gpt-5.2 using promptfoo, with a focus on performance, cost, and latency.
The end result will be a side-by-side comparison that looks similar to this:
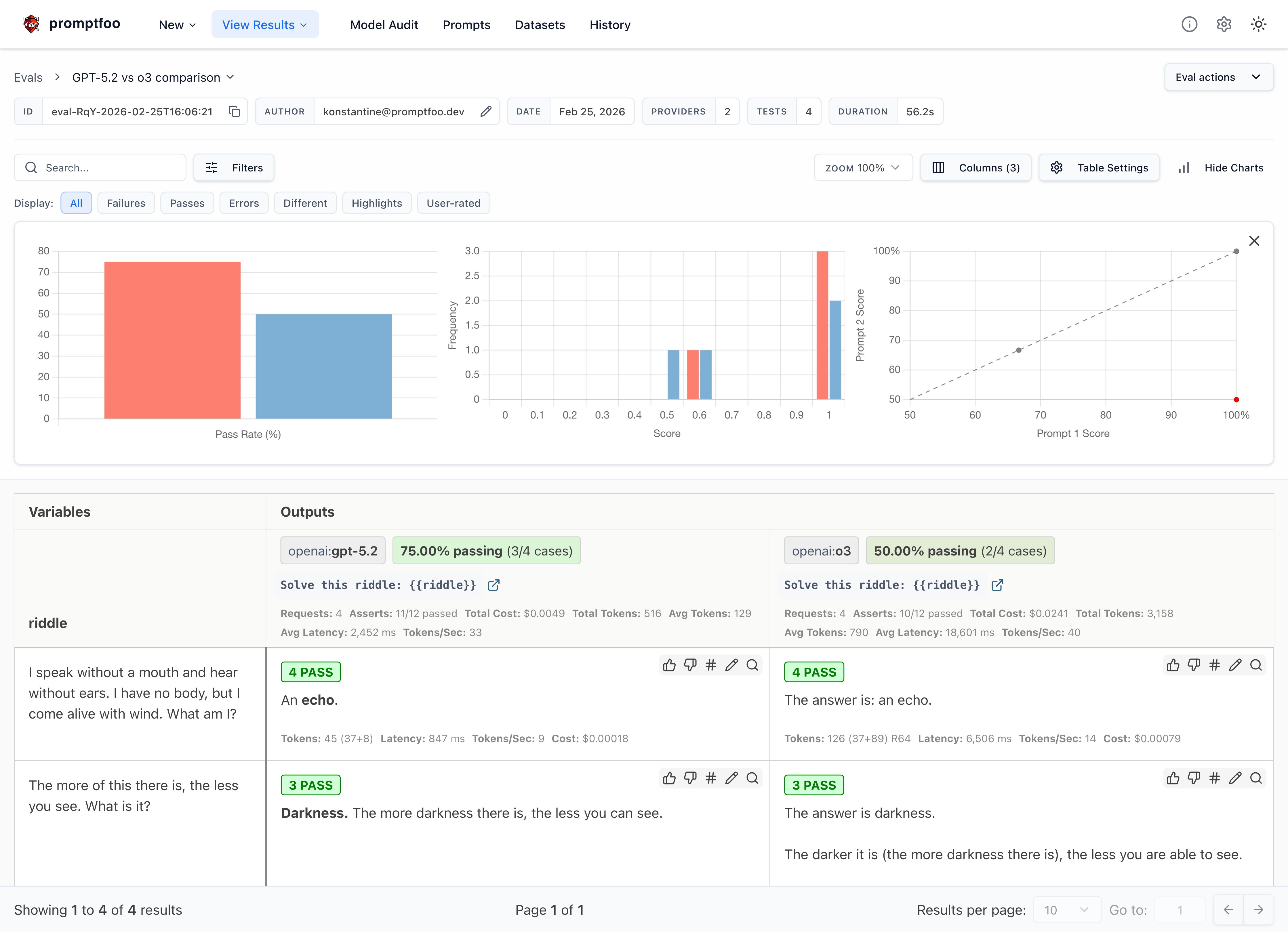
Prerequisites
Before we begin, you'll need:
- promptfoo CLI installed. If not, refer to the installation guide.
- An active OpenAI API key set as the
OPENAI_API_KEYenvironment variable.
Step 1: Setup
Create a new directory for your comparison project:
mkdir openai-o3-comparison
cd openai-o3-comparison
Step 2: Configure the Comparison
Create a promptfooconfig.yaml file to define your comparison.
-
Prompts: Define the prompt template that will be used for all test cases. In this example, we're using riddles:
prompts:
- 'Solve this riddle: {{riddle}}'The
{{riddle}}placeholder will be replaced with specific riddles in each test case. -
Providers: Specify the models you want to compare. In this case, we're comparing gpt-5.2 and o3:
providers:
- openai:gpt-5.2
- openai:o3 -
Default Test Assertions: Set up default assertions that will apply to all test cases. Given the cost and speed of o3, we're setting thresholds for cost and latency:
defaultTest:
assert:
# Inference should always cost less than this (USD)
- type: cost
threshold: 0.02
# Inference should always be faster than this (milliseconds)
- type: latency
threshold: 30000These assertions will flag any responses that exceed $0.02 in cost or 30 seconds in response time.
-
Test Cases: Now, define your test cases. In this specific example, each test case includes:
- The riddle text (assigned to the
riddlevariable) - Specific assertions for that test case (optional)
Here's an example of a test case with assertions:
tests:
- vars:
riddle: 'I speak without a mouth and hear without ears. I have no body, but I come alive with wind. What am I?'
assert:
- type: contains
value: echo
- type: llm-rubric
value: Do not apologizeThis test case checks if the response contains the word "echo" and uses an LLM-based rubric to ensure the model doesn't apologize in its response. See deterministic metrics and model-graded metrics for more details.
Add multiple test cases to thoroughly evaluate the models' performance on different types of riddles or problems.
- The riddle text (assigned to the
Now, let's put it all together in the final configuration:
description: 'GPT-5.2 vs o3 comparison'
prompts:
- 'Solve this riddle: {{riddle}}'
providers:
- openai:gpt-5.2
- openai:o3
defaultTest:
assert:
# Inference should always cost less than this (USD)
- type: cost
threshold: 0.02
# Inference should always be faster than this (milliseconds)
- type: latency
threshold: 30000
tests:
- vars:
riddle: 'I speak without a mouth and hear without ears. I have no body, but I come alive with wind. What am I?'
assert:
- type: contains
value: echo
- type: llm-rubric
value: Do not apologize
- vars:
riddle: 'The more of this there is, the less you see. What is it?'
assert:
- type: contains
value: darkness
- vars:
riddle: >-
Suppose I have a cabbage, a goat and a lion, and I need to get them across a river. I have a boat that can only carry myself and a single other item. I am not allowed to leave the cabbage and lion alone together, and I am not allowed to leave the lion and goat alone together. How can I safely get all three across?
- vars:
riddle: 'The surgeon, who is the boy''s father says, "I can''t operate on this boy, he''s my son!" Who is the surgeon to the boy?'
assert:
- type: llm-rubric
value: "output must state that the surgeon is the boy's father"
This configuration sets up a comprehensive comparison between gpt-5.2 and o3 using a variety of riddles, with cost and latency requirements. We strongly encourage you to revise this with your own test cases and assertions!
Step 3: Run the Comparison
Execute the comparison using the promptfoo eval command:
npx promptfoo@latest eval
This will run each test case against both models and output the results.
To view the results in a web interface, run:
npx promptfoo@latest view
What's next?
By running this comparison, you'll gain insights into how o3 performs against gpt-5.2 on tasks requiring logical reasoning and problem-solving. You'll also see the trade-offs in terms of cost and latency.
Reasoning models like o3 excel at complex multi-step problems, but for simpler tasks the extra thinking time and cost may not be worth it. GPT-5.2 is often the better choice when speed and cost matter more than deep reasoning.
Ultimately, the best model is going to depend a lot on your application. There's no substitute for testing these models on your own data, rather than relying on general-purpose benchmarks.